💡 문서 기반 질의응답이 가능한 RAG 시스템을 구현하여 포트폴리오 사이트에 적용한 기술적 구현 과정을 다룹니다.
개인 포트폴리오나 기업 문서에 대한 질의응답 기능은 방문자에게 효율적인 정보 접근을 제공할 수 있는 유용한 기능입니다. 일반적인 FAQ나 정적 문서와 달리, AI 기반 질의응답 시스템은 자연어 질문에 대해 문서 내용을 기반으로 한 정확하고 맥락적인 답변을 제공할 수 있습니다.
본 글에서는 RAG(Retrieval-Augmented Generation) 아키텍처를 활용하여 문서 학습 기반 질의응답 시스템을 구현한 과정을 기술적으로 분석하고, 실제 구현에서 마주한 주요 이슈들과 최적화 방법을 공유합니다.
RAG란 무엇인가
RAG(Retrieval-Augmented Generation)는 "검색 강화 생성"이라고 번역할 수 있습니다. 간단히 말하면 AI가 답변하기 전에 관련 문서를 먼저 찾아보고, 그 내용을 바탕으로 답변을 생성하는 방식입니다.
기존 AI vs RAG의 차이점
일반적인 ChatGPT 같은 LLM:
- 학습된 데이터만으로 답변
- 최신 정보나 특정 개인 정보는 모름
- 때로는 그럴듯한 거짓말(환각)을 만들어냄
RAG 시스템:
- 외부 문서에서 관련 정보를 실시간으로 검색
- 검색된 내용을 바탕으로 답변 생성
- 근거가 있는 답변이므로 신뢰성 높음
RAG 동작 원리
오프라인: 문서 수집 → 텍스트 분할 → 벡터로 변환 → 데이터베이스 저장
온라인: 사용자 질문 → 질문을 벡터로 변환 →
유사한 문서 검색 → 문서 + 질문을 AI에 전달 → 답변 생성
핵심은 벡터 임베딩을 통한 의미 검색입니다. 예를 들어:
- "개발자"와 "프로그래머"는 다른 단어지만 의미가 비슷
- 벡터 공간에서는 가까운 위치에 배치됨
- "프론트엔드 개발자"를 검색하면 "React 개발", "웹 개발" 등도 함께 찾아줌
이렇게 키워드 매칭이 아닌 의미 기반 검색이 가능해집니다.
기술 스택 선택과 고민
AI 모델 선택: Gemini를 택한 이유
여러 AI 모델을 비교해봤는데, 결정적인 요인은 비용이었습니다.
비용 비교 (2025년 기준):
- Gemini: 하루 1,500회 요청 무료 (Flash 모델), Pro 모델도 25-100회 무료
- OpenAI GPT-4: 무료 플랜 없음, 토큰당 비용이 상대적으로 높음
- Claude: 제한적인 무료 사용량, 유료 시 비쌈
개인 프로젝트에서 매달 API 비용을 지불하기는 부담스러웠습니다. Gemini의 무료 할당량이 가장 넉넉했고, 임베딩과 텍스트 생성을 하나의 API로 처리할 수 있어서 개발도 편했습니다.
프로덕션 환경에서는 API 호출량과 비용 효율성을 종합적으로 고려해야 합니다.
전체 아키텍처
포트폴리오 문서 (PDF, 텍스트)
↓
NestJS 백엔드 (문서 처리 + RAG 파이프라인)
↓
Pinecone (벡터 데이터베이스)
↓
Svelte 프론트엔드 (채팅 UI)
↓
Gemini API (임베딩 + 텍스트 생성)
기술 스택:
- 백엔드: NestJS (TypeScript)
- 프론트엔드: Svelte (TypeScript)
- 벡터 DB: Pinecone
- AI 모델: Google Gemini
- 배포: Vercel
벡터 데이터베이스 선택: ChromaDB vs Pinecone
벡터 데이터베이스로는 두 가지 옵션을 고려했습니다.
ChromaDB
- 장점: 무료, 로컬 개발 환경에서 쉬운 설정, Docker로 간단 실행
- 단점: 서버리스 환경에서 지속적 운영 어려움, 데이터 영속성 문제
- 적합한 환경: 로컬 개발, 프로토타이핑, 자체 서버 운영
개발 초기에는 ChromaDB를 로컬 Docker로 실행했습니다. 설정이 간단하고 무료라서 프로토타이핑에는 완벽했습니다.
하지만 Vercel 같은 서버리스 환경에서는 Docker 컨테이너를 지속적으로 유지할 수 없습니다. 함수가 실행될 때마다 새로운 컨테이너가 생성되고 사라지기 때문에, ChromaDB에 저장한 데이터가 사라지는 문제가 있었습니다.
Pinecone
- 장점: 클라우드 네이티브, 서버리스 환경에 최적화, 높은 성능과 확장성
- 단점: 유료 (무료 플랜 제한적), 외부 서비스 의존성
- 적합한 환경: 프로덕션 배포, 서버리스 아키텍처, 확장 가능한 서비스
Pinecone은 관리형 벡터 데이터베이스 서비스로, AWS/GCP 같은 클라우드 환경에 최적화되어 있습니다. 무료 플랜도 개인 프로젝트에는 충분했고, 서버리스 환경에서 안정적으로 동작합니다.
최종적으로 배포를 고려해서 Pinecone으로 전환했습니다.
구현 과정과 주요 이슈들
1. 문서 처리: 청킹(Chunking)의 중요성
첫 번째로 마주한 문제는 "문서를 어떻게 나눌 것인가"였습니다.
처음에는 포트폴리오 문서 전체를 하나의 임베딩으로 만들었습니다. 그런데 실제로 테스트해보니 결과가 엉망이었습니다.
문제상황:
- "React 프로젝트 경험이 있나요?" → "저는 다양한 기술을 다룹니다" (엉뚱한 답변)
- "어떤 회사에서 일했나요?" → "여러 프로젝트를 진행했습니다" (구체적이지 않음)
원인 분석: 문서가 너무 크면 임베딩할 때 세부 정보가 뭉개집니다. 5000자짜리 문서를 하나의 벡터로 만들면, "React"라는 키워드가 있어도 전체 맥락에 묻혀서 검색이 제대로 안 됩니다.
해결책: 문서를 1000자 단위로 분할(청킹)해서 각각 임베딩을 만들었습니다.
private splitTextIntoChunks(text: string): string[] {
const chunkSize = 1000;
const overlap = 100; // 앞뒤 100자씩 겹치게 해서 맥락 유지
const chunks: string[] = [];
for (let i = 0; i < text.length; i += chunkSize - overlap) {
chunks.push(text.substring(i, i + chunkSize));
}
return chunks;
}
결과: 청킹 후에는 훨씬 정확한 답변이 나오기 시작했습니다.
- "React 경험이 있나요?" → "React로 XX 프로젝트를 진행했습니다" (구체적이고 정확함)
2. 벡터 검색 최적화
두 번째 이슈는 검색 결과를 몇 개나 가져올 것인가였습니다.
실험 결과:
- 1개: 너무 적어서 맥락이 부족
- 5개 이상: 너무 많아서 관련 없는 내용까지 포함
- 3개: 적당히 관련성 높으면서도 충분한 정보 제공
최종적으로 상위 3개 검색 결과를 사용하기로 했습니다.
// Pinecone에서 유사한 문서 3개 검색
const results = await this.pineconeService.queryVectors(queryEmbedding, 3);
const relevantDocuments = results.map((match) => match.metadata.text);
3. 프롬프트 엔지니어링: 일관성 확보
세 번째 문제는 AI 응답의 일관성이었습니다.
초기 문제점:
- 같은 질문에도 매번 다른 스타일로 답변
- 때로는 존댓말, 때로는 반말
- 문서에 없는 내용을 상상해서 답변하기도 함
해결 과정: 매우 구체적이고 상세한 프롬프트를 작성했습니다.
const prompt = `
당신은 문서 작성자입니다. 다음 지침을 반드시 따라주세요:
1. 페르소나: 문서 작성자의 입장에서 1인칭으로 답변
2. 어조: 정중하고 친근한 존댓말 사용
3. 길이: 100자 내외로 간결하게 답변
4. 제약: 아래 제공된 정보만을 사용하여 답변
5. 예외: 정보가 없으면 "해당 내용은 답변드리기 어렵습니다"라고 응답
제공된 정보:
${context}
질문: ${query}
답변:`;
개선 효과:
- 일관된 어조와 스타일 유지
- 근거 없는 추측 답변 크게 감소
- 개발자 본인이 답변하는 느낌의 자연스러운 대화
4. 실제 성능 테스트
구현 완료 후 다양한 질문으로 테스트해봤습니다.
잘 동작하는 질문들:
- "어떤 기술 스택을 사용하시나요?" → 기술 문서에서 정확히 찾아서 답변
- "프로젝트 경험을 알려주세요" → 관련 프로젝트 정보를 적절히 요약해서 제공
- "회사 경력이 궁금해요" → 경력 관련 문서에서 정확한 정보 추출
한계가 있는 질문들:
- "개발자로서의 목표가 뭔가요?" → 추상적 질문은 문서 매칭이 어려움
- "왜 이 기술을 선택했나요?" → 의사결정 배경은 문서에 없으면 답변 불가
- "다른 개발자에게 조언해주세요" → 창의적 답변이 필요한 경우 제한적
정확도 평가: 약 80% 정도의 질문에는 만족할 만한 답변을 제공했습니다. 팩트 기반 질문에는 매우 강하지만, 개인적 견해나 추상적 내용에는 한계가 있었습니다.
실제 결과물
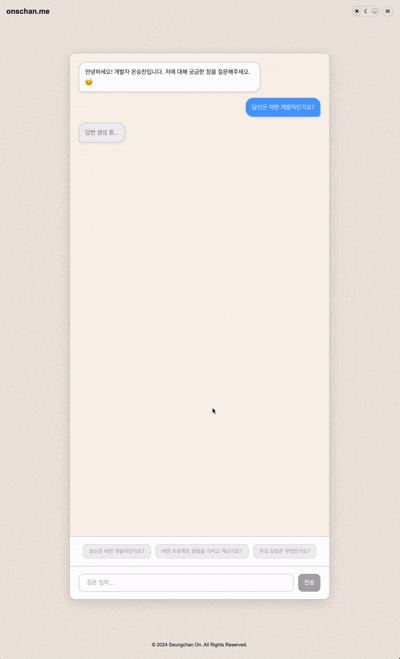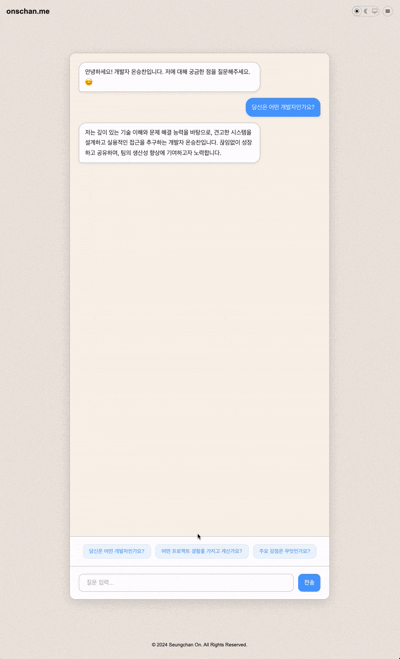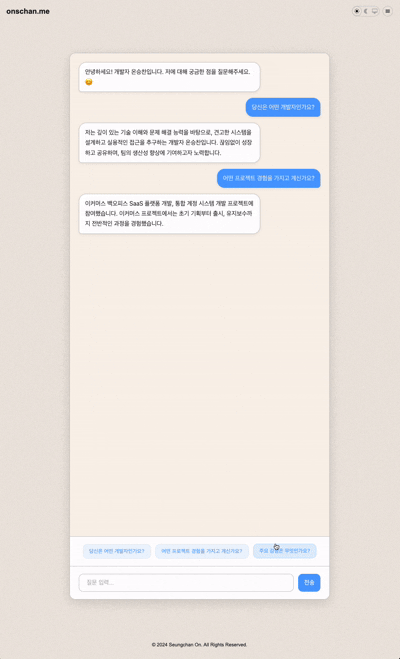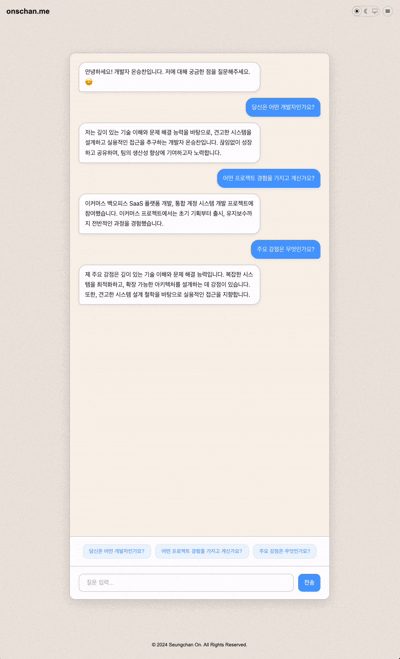
메뉴에 있는 AI Chatbot으로 접근하거나 해당 링크에서 직접 확인해볼 수 있습니다.
개발하면서 배운 것들
RAG는 생각보다 단순하다
처음에는 RAG가 복잡한 AI 기술일 줄 알았는데, 실제로는 "문서 검색 + AI 답변"의 단순한 조합이었습니다. 하지만 각 단계에서 세밀한 튜닝이 필요했습니다.
중요한 설계 포인트들:
- 문서 청킹 크기 (1000자가 적절했음)
- 검색 결과 개수 (3개가 최적)
- 프롬프트 구성 (매우 구체적으로 작성해야 함)
- 벡터 DB 선택 (배포 환경 고려 필수)
데이터 품질이 결과를 좌우한다
아무리 좋은 AI 모델을 써도 학습할 문서가 부실하면 답변도 부실합니다. 포트폴리오 문서를 정리하고 구조화하는 작업이 생각보다 중요했습니다.
좋은 문서 작성법:
- 구체적인 수치와 사실 위주로 작성
- 중복되는 내용 최소화
- 질문될 만한 내용들을 미리 포함
- 일관된 톤앤매너 유지
AI는 완벽하지 않다는 걸 받아들이기
RAG를 직접 구현해보니 AI의 한계가 명확히 보였습니다. 80% 정도의 질문에는 좋은 답변을 주지만, 나머지 20%는 여전히 어렵습니다.
현실적인 기대치 설정:
- 팩트 기반 질문: 매우 잘함
- 추상적/창의적 질문: 한계 있음
- 대화 맥락 기억: 현재 버전에서는 불가능
- 최신 정보: 문서에 없으면 답변 불가
마무리
RAG를 직접 구현해보면서 AI 기술이 점점 개인 개발자에게도 접근 가능해지고 있다는 걸 실감했습니다. 복잡해 보이지만 실제로는 기존 기술들의 조합이고, 조금만 공부하면 개인 프로젝트 수준에서도 충분히 만들 수 있습니다.
무엇보다 "내 데이터로 내만의 AI를 만들 수 있다"는 점이 흥미로웠습니다. ChatGPT처럼 범용적인 AI도 좋지만, 특정 도메인에 특화된 AI의 가능성도 크다고 생각합니다.
이번 프로젝트는 완벽하지 않지만, RAG라는 기술을 직접 경험해볼 수 있는 좋은 기회였습니다. 앞으로 이런 개인화된 AI 어시스턴트가 더 많아질 것 같고, 개발자로서도 흥미로운 영역이라고 생각합니다.
